
Mieux gérer vos vulnérabilités pour protéger votre activité
Votre entreprise peut-elle vraiment se permettre une interruption d'activité totale à cause d'un simple mot de passe faible ou…
Lire l'article →
 Par Vivien · Consultant SEO
📅 7 mars 2026
⏱ 16 min de lecture
Par Vivien · Consultant SEO
📅 7 mars 2026
⏱ 16 min de lecture

L’essentiel à retenir : Un plan de réponse aux incidents (PRI) est vital pour stopper une cyberattaque avant qu’elle ne paralyse l’activité. Ce dispositif structure la réaction technique et humaine pour minimiser les pertes financières et réputationnelles. Adopter cette stratégie proactive permet d’éviter la panique, sachant qu’une entreprise met en moyenne trois semaines à se remettre d’une intrusion.
Craignez-vous de voir votre activité s’arrêter net suite à une intrusion numérique malveillante ? Un incident response plan structuré permet de transformer le chaos d’une cyberattaque en une série d’actions maîtrisées pour protéger vos données et votre réputation. Vous découvrirez ici les six étapes clés pour bâtir une défense solide et les outils d’automatisation capables de stopper l’hémorragie avant qu’elle ne devienne un désastre financier.
Face aux menaces numériques, la question n’est plus de savoir si on sera attaqué, mais quand, ce qui justifie l’existence d’une stratégie de défense proactive.
La réponse aux incidents (PRI) se focalise sur l’extinction du feu immédiat. Elle vise à stopper l’attaquant avant qu’il ne s’installe. Le plan de reprise (PRA) intervient plus tard. Il reconstruit les serveurs après la bataille.
PRI (Réponse Incident)
Focus : Extinction immédiate du feu et arrêt de l’attaquant pour limiter les dégâts.
PRA (Reprise Sinistre)
Focus : Reconstruction des serveurs et continuité métier après la crise majeure.
Ces deux approches forment un bouclier complet. Sans PRI, le pirate reste dans le réseau. Sans PRA, l’entreprise reste à l’arrêt total. Ils sont donc indissociables.

La résilience dépend de cette coordination. Le premier gère la crise cyber pure. Le second assure la survie métier. C’est une question de timing et d’objectifs.
L’impact financier direct est lié au temps de réaction. Chaque minute de détection supplémentaire augmente la facture finale. Les coûts explosent si l’exfiltration de données sensibles est massive.
La confiance des clients s’effrite vite. Une communication floue ou tardive ruine des années de marketing. La transparence devient alors votre meilleure arme de survie.
Voici les points noirs qui pèsent sur votre budget lors d’un incident :
Il faut des critères objectifs pour trier les alertes. Toutes les notifications ne se valent pas. Il faut séparer le bruit de fond des véritables menaces critiques.
Une matrice de décision aide les analystes. On croise l’impact métier avec la probabilité de succès de l’attaque. Cela permet d’allouer les ressources humaines là où l’urgence est réelle.
L’automatisation du triage initial est capitale. Les outils doivent pré-mâcher le travail pour éviter la saturation. L’humain ne doit intervenir que sur les cas complexes.
Une fois l’importance du plan comprise, il faut se pencher sur l’humain, car ce sont les hommes et les femmes qui font la différence en pleine tempête.

Définir les rôles au sein de la cellule de crise est vital. Les analystes techniques fouillent les logs en profondeur. La direction prend les décisions stratégiques lourdes tandis que le juridique gère les contrats.
Clarifier le processus de prise de décision rapide est indispensable. Qui a le pouvoir de couper Internet ? Cette question doit avoir une réponse avant l’incident. L’ambiguïté est l’alliée des pirates informatiques.
Membres essentiels du CSIRT
Apprendre à parler le langage de la finance change tout. On ne vend pas des pare-feu, on protège concrètement le chiffre d’affaires. Le plan devient alors une assurance pour la continuité d’activité.
Utilisez des indicateurs de performance (KPI) vraiment percutants. Montrez le temps moyen de réponse actuel face aux risques. Comparez-le aux standards du marché. Un investissement ciblé réduit drastiquement ces délais dangereux.
Le soutien n’est pas uniquement financier. La direction doit valider les politiques de sécurité publiquement. Cela renforce l’autorité de l’équipe cyber auprès de tous les employés de la structure.
La fatigue cognitive des analystes en période de crise est un danger réel. Travailler vingt heures d’affilée mène à l’erreur fatale. Il faut instaurer des rotations strictes pour maintenir la lucidité.
Identifier les signes de stress intense au sein du SOC est primordial. Une baisse de communication ou une irritabilité inhabituelle sont des alertes. Le management doit protéger ses experts pour durer.
Proposer des solutions de renfort externe aide à tenir. Faire appel à un prestataire spécialisé permet de souffler. L’externalisation partielle est une soupape de sécurité indispensable pour les petites structures.
Audit SEO offert (30 min) : je vous montre exactement ce qui bloque votre visibilité sur Google — et comment vos concurrents en profitent chaque jour.
Pour que l’équipe agisse comme une machine bien huilée, elle doit suivre une méthodologie rigoureuse, souvent inspirée des cadres SANS ou NIST.
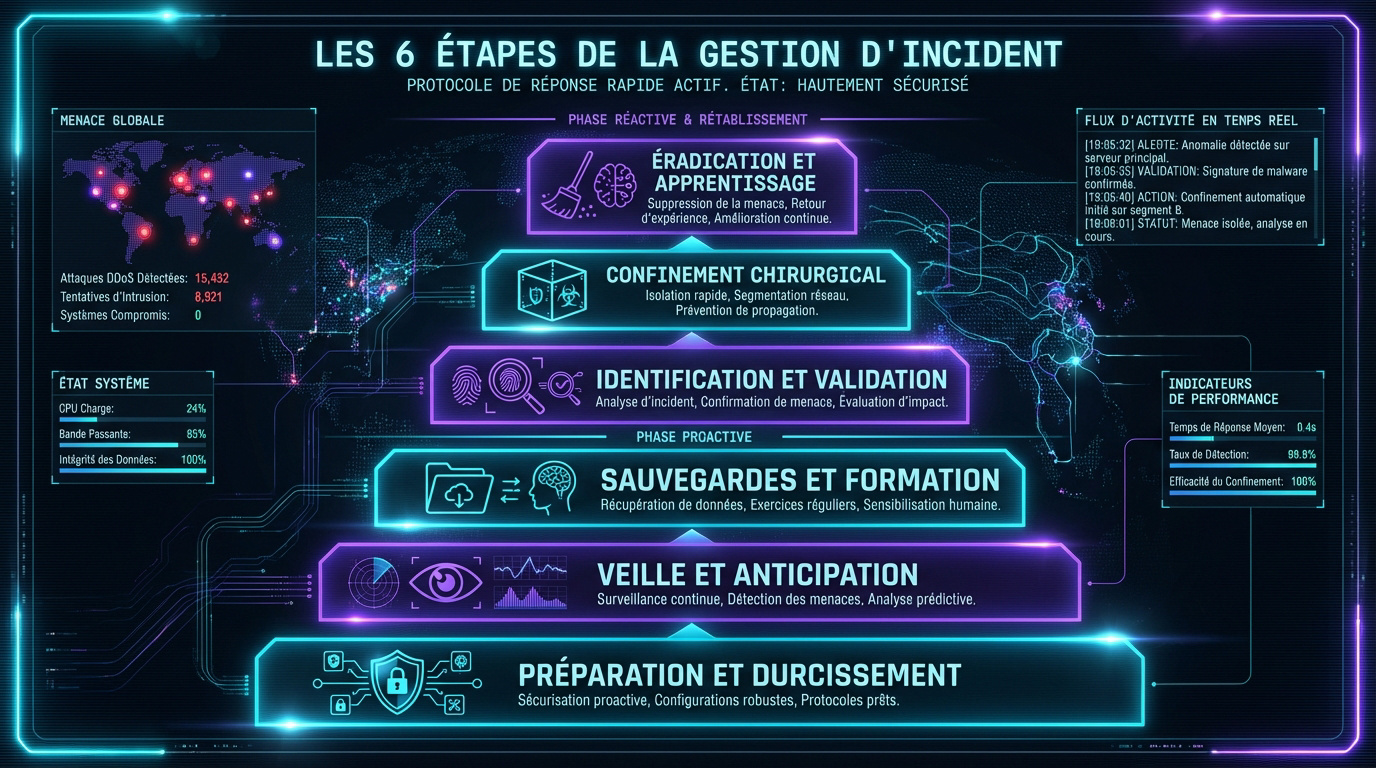
La préparation est le socle de tout le plan. Il faut appliquer des mesures de hardening strictes partout. Désactivez les services inutiles sur vos serveurs sensibles. Réduisez la surface d’attaque avant que l’ennemi ne frappe.
Mettre en place une veille active sur les menaces (Threat Intelligence). Anticipez les nouveaux vecteurs d’attaque en observant les tendances mondiales. Savoir c’est déjà un peu pouvoir se défendre.
Vérifier régulièrement les sauvegardes et les accès. Un système durci mais non sauvegardé reste vulnérable. La préparation inclut aussi la formation continue des utilisateurs aux risques numériques.
Valider la réalité de l’intrusion avec des indicateurs de compromission (IoC). Ne paniquez pas sur une fausse alerte. Utilisez des preuves techniques solides pour confirmer la brèche.
Isoler les segments réseau compromis immédiatement. L’objectif est de couper la route à l’attaquant. Ne paralysez pas toute l’entreprise si un seul département est touché. Le confinement doit être chirurgical et rapide.
Documenter chaque action prise durant cette phase critique. Ces notes serviront plus tard pour l’analyse forensique. La précision temporelle est vitale pour comprendre le cheminement de l’intrus.
Nettoyer les systèmes en profondeur après le confinement. Supprimez les portes dérobées laissées par les pirates. Restaurez les données uniquement à partir de sauvegardes vérifiées et saines.
Analyser les enseignements tirés de l’incident. Pourquoi l’attaque a-t-elle réussi cette fois ? Identifiez les failles organisationnelles ou techniques. Ce retour d’expérience transforme une défaite en une future victoire.
| Phase | Action Clé | Objectif Principal | Livrable |
|---|---|---|---|
| Préparation | Audit et hardening | Réduire les vulnérabilités | Politique de sécurité |
| Identification | Analyse des IoC | Confirmer l’incident | Rapport d’alerte |
| Confinement | Isolation réseau | Stopper la propagation | Registre des accès coupés |
| Éradication | Nettoyage malware | Supprimer la menace | Certificat de nettoyage |
| Récupération | Restauration backup | Reprendre l’activité | Rapport de remise en ligne |
| Post-incident | Debriefing | Améliorer le futur | Document leçons apprises |
Le conseil de Rina
Vous voyez le problème ? Sans un incident response plan, la panique prend le dessus. Plus de 8 000 éditeurs risquent gros chaque année par simple manque de structure. Ne soyez pas les prochains.
La théorie est utile, mais face à l’urgence, des fiches réflexes ou « playbooks » sont indispensables pour ne pas perdre de précieuses secondes.
Réagir instantanément dès qu’un vol d’identifiant est suspecté. Révoquez tous les accès de l’utilisateur concerné. Changez les mots de passe et réinitialisez les doubles authentifications compromises.
Analyser l’email malveillant pour bloquer les domaines émetteurs. Identifiez si d’autres collaborateurs ont reçu le même message. Une recherche proactive dans les boites mails évite une propagation silencieuse du malware.
Sensibiliser la victime sans la blâmer. Expliquez-lui les signes qu’elle a manqués. L’humain est le premier capteur de votre système de détection, traitez-le comme tel.
Évaluer l’ampleur du chiffrement sur le réseau. Identifiez quels serveurs sont touchés et si des données ont fuité. L’exfiltration est souvent plus grave que le simple blocage.
Attention sur la rançon
Payer une rançon ne garantit jamais la récupération de vos données. Cette décision doit être tranchée par la direction avant qu’un incident ne survienne.
Définir une position ferme sur le paiement des rançons. La direction doit trancher cette question éthique et financière à l’avance. Payer ne garantit jamais la récupération totale de vos fichiers.
Isoler les sauvegardes hors ligne immédiatement. Vérifiez qu’elles n’ont pas été corrompues par l’attaquant. La survie de l’entreprise dépend de l’intégrité de ces copies de sécurité.
Détecter les comportements anormaux grâce aux journaux d’audit. Un employé qui télécharge des gigaoctets de données à minuit est suspect. Surveillez les accès aux répertoires les plus sensibles.
Appliquer strictement le principe du moindre privilège. Un utilisateur ne doit accéder qu’au strict nécessaire pour son travail. Cela limite naturellement les dégâts en cas de compte compromis ou malveillant.
Mener des entretiens discrets en cas de doute sérieux. Collaborez étroitement avec les ressources humaines. La gestion d’une menace interne demande autant de psychologie que de technique pure.
| Type de Menace | Action Prioritaire |
|---|---|
| Phishing | Révocation immédiate des accès et reset MFA. |
| Ransomware | Isolation des systèmes et vérification des backups. |
| Menace Interne | Audit des logs et application du moindre privilège. |
En intégrant ces procédures dans votre incident response plan, vous évitez la panique qui coûte cher. Pour nous, Malgaches de la diaspora ou entrepreneurs, protéger nos outils numériques, c’est aussi sécuriser nos liens et nos projets avec le pays. Restez vigilants, car la sécurité est l’affaire de tous.

Pour gagner la course contre les scripts automatisés des attaquants, la défense doit elle aussi s’armer d’outils technologiques performants.
Centraliser tous les logs via un SIEM performant est un premier pas. Vous obtenez ainsi une visibilité totale sur votre infrastructure. Sans cette vue d’ensemble, vous restez aveugle face aux mouvements latéraux.
Utiliser le SOAR pour automatiser les tâches répétitives change la donne. Laissez la machine bloquer les IP suspectes ou isoler un poste automatiquement. Cela libère un temps précieux pour vos experts sur les analyses complexes.
Affiner les règles de corrélation permet de réduire drastiquement les faux positifs. Trop d’alertes tue l’alerte, c’est bien connu. L’automatisation doit simplifier la vie de l’analyste, pas la noyer sous le bruit.
Garantir l’intégrité des données est vital pour les futures poursuites. Ne touchez pas aux machines infectées sans précaution. La preuve numérique est fragile et s’altère au moindre redémarrage non maîtrisé.
Utiliser des outils d’imagerie disque professionnels est la norme. Créez des copies bit à bit des supports de stockage. Travaillez toujours sur la copie pour préserver l’original. C’est la base de toute enquête sérieuse.
Documenter la chaîne de possession de chaque preuve évite bien des déboires. Notez qui a manipulé quoi et à quel moment. Cette rigueur est indispensable pour que les preuves soient recevables en justice.
Gérer les ressources éphémères demande une rigueur particulière. Un serveur compromis peut disparaître en quelques secondes. Configurez vos logs pour qu’ils soient exportés hors de l’instance immédiatement.
Comprendre le modèle de responsabilité partagée avec votre fournisseur est un point de vigilance. Qui gère la sécurité de l’hyperviseur ? Qui gère celle des données ? Ne laissez aucune zone d’ombre dans votre contrat.
Ajuster vos outils de détection aux APIs spécifiques est une priorité. Le cloud demande une surveillance des configurations autant que du trafic réseau. Un bucket S3 ouvert est souvent la porte d’entrée principale.
Enfin, un plan n’est complet que s’il respecte le cadre légal et s’il a survécu à l’épreuve du feu lors de simulations réalistes.
Identifiez les autorités à alerter sous 72 heures. Le chronomètre démarre dès la connaissance de la fuite. Préparez vos modèles de notification à l’avance pour gagner du temps.
Alerte légale
Le délai de 72 heures pour notifier la CNIL est le maximum pour transmettre une première analyse.
Rassemblez les preuves pour la CNIL en détaillant la nature des données volées. Une notification incomplète peut entraîner des sanctions lourdes pour votre organisation.
Informez les victimes si le risque est élevé. La transparence limite votre responsabilité juridique et protège vos clients.
Coordonnez les messages pour vos employés afin d’éviter les rumeurs. Donnez des consignes claires sur ce qu’ils peuvent dire ou non en public.
Un porte-parole unique doit centraliser la parole officielle auprès des médias. Préparez des communiqués factuels pour garder le contrôle du récit médiatique et rassurer vos partenaires.
Surveillez les réseaux sociaux en temps réel. Répondez aux inquiétudes légitimes sans entrer dans des débats techniques stériles.
Organisez des exercices sur table pour tester la coordination entre départements. C’est le meilleur moyen de repérer les failles logiques dans vos procédures actuelles.
Lancez des attaques simulées avec une équipe de Red Teaming. Mettez vos défenses à l’épreuve du monde réel pour vérifier l’efficacité de vos outils de détection.
Bénéfices
Risques
Mettez à jour votre incident response plan après chaque test. Un document statique est inutile ; l’amélioration continue garantit votre résilience.
Face aux cybermenaces, un plan d’intervention en cas d’incident bien rodé limite l’impact financier et protège votre réputation. En structurant vos six étapes clés et vos équipes, vous transformez la panique en une défense chirurgicale. Agissez dès maintenant pour sécuriser votre futur : une préparation rigoureuse est votre meilleur bouclier.
Un plan de réponse aux incidents (PRI) est un document stratégique qui sert de guide de survie face aux cyberattaques. Il définit précisément les rôles de chacun, les responsabilités et les étapes techniques à suivre pour neutraliser une menace. C’est un outil indispensable pour agir avec calme et méthode au lieu de céder à la panique lors d’une crise.
L’importance de ce plan réside dans sa capacité à minimiser les interruptions de vos activités et à protéger la réputation de votre structure. En réagissant vite et bien, vous évitez des erreurs humaines coûteuses et vous vous mettez à l’abri de lourdes sanctions légales liées à la protection des données.
La gestion d’un incident se décompose généralement en six phases cruciales. Tout commence par la préparation, où l’on durcit les systèmes, suivie de l’identification pour confirmer la réalité de la menace. Vient ensuite le confinement, une étape chirurgicale visant à isoler les systèmes touchés pour stopper la propagation de l’attaque vers d’autres secteurs de l’entreprise.
Une fois la menace isolée, on passe à l’éradication pour supprimer les malwares, puis à la récupération pour restaurer les données et surveiller le retour à la normale. Enfin, la phase de post-incident est essentielle : elle permet de tirer les leçons de l’événement afin de renforcer vos défenses pour l’avenir.
Bien que complémentaires, ces deux notions interviennent à des moments différents. La réponse aux incidents est une approche tactique et immédiate : on cherche à éteindre le feu, détecter la brèche et limiter les dégâts instantanés. C’est une action proactive et réactive face à un événement précis pour rétablir les services au plus vite.
La reprise après sinistre (PRA) est une stratégie plus globale. Elle intervient après une catastrophe majeure (catastrophe naturelle ou attaque massive) pour reconstruire l’infrastructure complète. Le PRA se concentre sur la survie à long terme et la restauration des fonctions critiques à partir d’un site de secours, en respectant des objectifs de temps de récupération (RTO).
Les conséquences financières sont souvent colossales. Au Canada, le coût moyen d’une violation de données a dépassé les 7 millions de dollars en 2025. Cela inclut les coûts directs comme les frais d’experts en cybersécurité (facturés entre 200 et 600 dollars l’heure) et les frais juridiques, mais aussi les amendes réglementaires qui peuvent atteindre 4 % du chiffre d’affaires mondial.
Il ne faut pas oublier les coûts indirects et cachés, tels que la perte de productivité durant les 23 jours d’arrêt moyen ou l’augmentation des primes d’assurance. Pour une PME, une rançon dépassant souvent le million de dollars peut tout simplement mener à l’insolvabilité, sans oublier la perte de confiance des clients qui est parfois irréparable.
En 2025, l’IA est devenue une arme à double tranchant. Les cybercriminels l’utilisent pour industrialiser leurs attaques, notamment en créant des emails de phishing hyper-personnalisés qui imitent parfaitement votre ton et vos logos. Cela rend les filtres de sécurité traditionnels beaucoup moins efficaces face à ces messages trompeurs générés à grande échelle.
Cependant, l’IA aide aussi les défenseurs. Elle est au cœur des solutions modernes comme le SOAR ou le SIEM, permettant d’analyser des milliers d’alertes quotidiennes et d’automatiser le blocage des menaces connues. Cette course technologique oblige les entreprises à adopter des outils de détection avancés pour ne pas rester aveugles face à des scripts automatisés de plus en plus sophistiqués.
Une grille de triage est un outil d’aide à la décision qui permet de classer les alertes par ordre de priorité. Elle utilise des critères objectifs comme la nature de la menace, la sensibilité des données visées et la criticité du serveur touché. Cela permet à vos équipes de ne pas se laisser submerger par le « bruit » des alertes mineures.
Grâce à cette grille, une intrusion sur un serveur contenant des fichiers clients sera immédiatement traitée en haute priorité, tandis qu’un incident sur un poste de travail isolé pourra attendre. C’est le premier filtre indispensable pour allouer vos ressources humaines là où l’urgence est réelle et minimiser l’impact sur votre organisation.
Chaque mois d'attente, ce sont des clients qui choisissent vos concurrents. Parlons de votre projet : audit gratuit, conseils concrets, zéro engagement.
6+ ans d'expérience en référencement naturel. J'aide les entreprises à transformer Google en canal d'acquisition rentable. En savoir plus · Me contacter
Votre entreprise peut-elle vraiment se permettre une interruption d'activité totale à cause d'un simple mot de passe faible ou…
Face à l'explosion du phishing et des ransomwares, craignez-vous que vos défenses actuelles ne soient plus qu'un lointain…
Votre entreprise pourrait-elle survivre à une cyberattaque majeure ou une inondation paralysant vos opérations demain matin ? Ce…

